install.packages("janitor")Limpando dados com {janitor}
Ferramentas poderosas para facilitar a hora da faxina.
O pacote {janitor} possui um grande número de funções feitas para faciliar nosso trabalho de limpeza de dados. Vamos explorar algumas das funcionalidades mais úteis deste pacote.
Conhecendo o {janitor}
O {janitor} possui diversas funções com o objetivo de nos ajudar a limpar dados de maneira mais rápida e direta, poupando neurônios para as partes mais divertidas da análise de dados.
{janitor}, apesar de não ser considerado parte do universo do {tidyverse}, é considerado um pacote tidyverse-oriented, funcionando como uma luva em pipe chains (|>) e com os pacotes {readr} e {readxl}.
Não há mistério para instalar o {janitor}, basta apenas uma linha de código:
Para carregar o pacote em conjunto com todas as suas funções, também é necessário apenas uma linha de código:
library(janitor)
#>
#> Attaching package: 'janitor'
#> The following objects are masked from 'package:stats':
#>
#> chisq.test, fisher.testTambém iremos usar os pacotes do {tidyverse} e o {readxl}:
library(readxl)
library(tidyverse)
#> ── Attaching core tidyverse packages ───────────────────── tidyverse 2.0.0 ──
#> ✔ dplyr 1.2.0 ✔ readr 2.2.0
#> ✔ forcats 1.0.1 ✔ stringr 1.6.0
#> ✔ ggplot2 4.0.2 ✔ tibble 3.3.1
#> ✔ lubridate 1.9.5 ✔ tidyr 1.3.2
#> ✔ purrr 1.2.1
#> ── Conflicts ─────────────────────────────────────── tidyverse_conflicts() ──
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ dplyr::lag() masks stats::lag()
#> ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorsUsando as ferramentas em nossa disposição
Agora que estamos preparados para a ação, vamos importar uma planilha de Excel com o pacote {readxl}. Para mais detalhes sobre o {readxl}, recomendo o blogpost sobre o readxl.
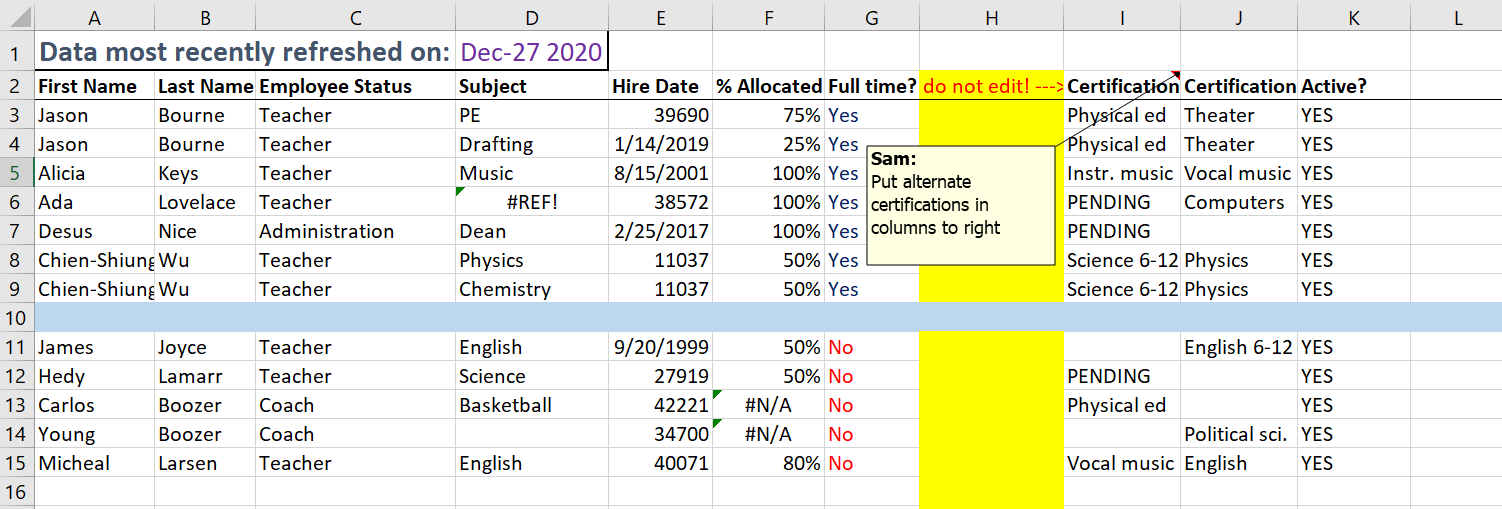
Ao observar a planilha, é possível notar alguns problemas:
- Um header na primeira linha, acima da tabela de fato, o que é inútil para nós
- Nomes de colunas de gosto questionável
- Colunas e linhas contendo formatação do excel, mas vazias
- Existe uma coluna que contém apenas “YES”, ou seja, não possui nenhuma informação e deverá ser removida
- Datas em diferentes formatos, mas em uma única coluna
Pulando linhas e limpando nomes
Ao importar esta planilha, logo percebemos que os nomes das colunas ficam um caos:
dirty_data <- read_excel("data/dirty_data.xlsx")
#> New names:
#> • `` -> `...2`
#> • `` -> `...3`
#> • `` -> `...5`
#> • `` -> `...6`
#> • `` -> `...7`
#> • `` -> `...8`
#> • `` -> `...9`
#> • `` -> `...10`
#> • `` -> `...11`
dirty_data
#> # A tibble: 14 × 11
#> Data most recently refr…¹ ...2 ...3 `Dec-27 2020` ...5
#> <chr> <chr> <chr> <chr> <chr>
#> 1 First Name Last Name Employee Status Subject Hire Date
#> 2 Jason Bourne Teacher PE 39690
#> 3 Jason Bourne Teacher Drafting 43479
#> 4 Alicia Keys Teacher Music 37118
#> 5 Ada Lovelace Teacher <NA> 38572
#> 6 Desus Nice Administration Dean 42791
#> # ℹ 8 more rows
#> # ℹ abbreviated name: ¹`Data most recently refreshed on:`Isso se deve devido a primeira linha do arquivo excel possuir um título (header). Podemos resolver isto apenas pulando a primeira linha com o parâmetro skip do read_excel():
dirty_data <- read_excel("data/dirty_data.xlsx", skip = 1)
dirty_data
#> # A tibble: 13 × 11
#> `First Name` `Last Name` `Employee Status` Subject `Hire Date`
#> <chr> <chr> <chr> <chr> <dbl>
#> 1 Jason Bourne Teacher PE 39690
#> 2 Jason Bourne Teacher Drafting 43479
#> 3 Alicia Keys Teacher Music 37118
#> 4 Ada Lovelace Teacher <NA> 38572
#> 5 Desus Nice Administration Dean 42791
#> 6 Chien-Shiung Wu Teacher Physics 11037
#> # ℹ 7 more rows
#> # ℹ 6 more variables: `% Allocated` <dbl>, `Full time?` <chr>, …Desta forma temos melhores nomes para as variáveis, mas eles ainda não são ideais para trabalhar. Para lidar com isso, podemos usufruir de um pouco da mágica do {janitor} com a função clean_names():
dirty_data <- read_excel("data/dirty_data.xlsx", skip = 1)
dirty_data |>
clean_names()
#> # A tibble: 13 × 11
#> first_name last_name employee_status subject hire_date percent_allocated
#> <chr> <chr> <chr> <chr> <dbl> <dbl>
#> 1 Jason Bourne Teacher PE 39690 0.75
#> 2 Jason Bourne Teacher Drafting 43479 0.25
#> 3 Alicia Keys Teacher Music 37118 1
#> 4 Ada Lovelace Teacher <NA> 38572 1
#> 5 Desus Nice Administration Dean 42791 1
#> 6 Chien-Shiung Wu Teacher Physics 11037 0.5
#> # ℹ 7 more rows
#> # ℹ 5 more variables: full_time <chr>, do_not_edit <lgl>, …Ótimo! nosso data.frame está tomando forma com apenas um parâmetro e uma função. Porém, se lembrarmos bem, ainda há colunas vazias, linhas vazias e colunas com valores constantes.
Removendo observações vazias, variáveis vazias e valores constantes
Para lidar com observações ou variáveis vazias, o {janitor} nos dá a função remove_empty():
dirty_data <- read_excel("data/dirty_data.xlsx", skip = 1)
dirty_data |>
clean_names() |>
remove_empty()
#> # A tibble: 12 × 10
#> first_name last_name employee_status subject hire_date percent_allocated
#> <chr> <chr> <chr> <chr> <dbl> <dbl>
#> 1 Jason Bourne Teacher PE 39690 0.75
#> 2 Jason Bourne Teacher Drafting 43479 0.25
#> 3 Alicia Keys Teacher Music 37118 1
#> 4 Ada Lovelace Teacher <NA> 38572 1
#> 5 Desus Nice Administration Dean 42791 1
#> 6 Chien-Shiung Wu Teacher Physics 11037 0.5
#> # ℹ 6 more rows
#> # ℹ 4 more variables: full_time <chr>, certification_9 <chr>, …Note que a tibble deixou de ter 13 observações e 11 variáveis para 12 observações e 10 variáveis.
Já a coluna “Active” na nossa planilha possui apenas um valor constante, “YES”, efetivamente não possuindo nenhuma informação relevante para nós. Para estes casos, janitor oferece remove_constant():
dirty_data <- read_excel("data/dirty_data.xlsx", skip = 1)
dirty_data |>
clean_names() |>
remove_empty() |>
remove_constant()
#> # A tibble: 12 × 9
#> first_name last_name employee_status subject hire_date percent_allocated
#> <chr> <chr> <chr> <chr> <dbl> <dbl>
#> 1 Jason Bourne Teacher PE 39690 0.75
#> 2 Jason Bourne Teacher Drafting 43479 0.25
#> 3 Alicia Keys Teacher Music 37118 1
#> 4 Ada Lovelace Teacher <NA> 38572 1
#> 5 Desus Nice Administration Dean 42791 1
#> 6 Chien-Shiung Wu Teacher Physics 11037 0.5
#> # ℹ 6 more rows
#> # ℹ 3 more variables: full_time <chr>, certification_9 <chr>, …Tratando datas
Para lidar com problemas de formatação de datas do Excel, podemos usar a função excel_numeric_to_date() para a coluna “hire_date”
dirty_data <- read_excel("data/dirty_data.xlsx", skip = 1)
dirty_data |>
clean_names() |>
remove_empty() |>
remove_constant() |>
mutate(hire_date = excel_numeric_to_date(hire_date))
#> # A tibble: 12 × 9
#> first_name last_name employee_status subject hire_date
#> <chr> <chr> <chr> <chr> <date>
#> 1 Jason Bourne Teacher PE 2008-08-30
#> 2 Jason Bourne Teacher Drafting 2019-01-14
#> 3 Alicia Keys Teacher Music 2001-08-15
#> 4 Ada Lovelace Teacher <NA> 2005-08-08
#> 5 Desus Nice Administration Dean 2017-02-25
#> 6 Chien-Shiung Wu Teacher Physics 1930-03-20
#> # ℹ 6 more rows
#> # ℹ 4 more variables: percent_allocated <dbl>, full_time <chr>, …Agora sim! Se notarmos a coluna “hire_date”, podemos ver que as datas estão todas lá, em formato <date> que podemos trabalhar. E desta forma, temos uma tibble que está pronta para o processamento dos dados com qualquer fim!